It’s time – past time – to wrap this up. I’ve been focused on the question of why critical rationalist methodology didn’t prevent its proponents from making confident proclamations that were wrong. I’ve concentrated on matters of personality, habit, and bias that, to put it charitably, directed their attention away from important facts and classes of facts.
In this post, I’ll use an analogy from a reader to argue that the methodology is fundamentally too incomplete to be workable. I claim that even someone with the purest of intentions, best intuition, highest intelligence, greatest imagination, and best work ethic could not follow critical rationalism and contribute to the growth of science.
Attempts to apply critical rationalism outside science will fare no better.

Mastodon user @interstar sent me this comment:
You are approaching this like an engineer asking “how might I implement a working model of a scientist?”, whereas Popper is more like the system architect designing an API or interface : “What’s the minimum contract something would have to support to still be a scientist?”
I don’t know if I agree with the characterization of me, but it’s certainly both fair and plausible. I’m also not sure that was Popper’s goal, but it’s definitely a useful lens on critical rationalism.
API?
This blog isn’t just for software people, so I’ll briefly explain what an API is. Skip this if you already know.
 Click to enlarge in a new tab.
Click to enlarge in a new tab.
An API is described by two sets of names. The first names actions or “functions.” One such function might allow you to open a file for later use. An app might use it like this:
open_file("my file", ToRead)
open_file is the function name. The first argument ("my file") is the name of the file, and the second (ToRead) is some datum that tells whether the file is to be opened read-only, for writing but not reading, or both.
open_file’s two arguments are of different data types. A name of a file isn’t the same thing as a counting number is not the same thing as an indication of whether a file is ToRead, ToWrite, or ToReadOrWrite.
 Click to enlarge in a new tab.
Click to enlarge in a new tab.
open_file exists, and (2) what type of arguments it uses and in what order. That’s provided by documentation such as that in the sidebar, which will typically begin with information something like this:
open_file(FileNamed name, ForPurpose purpose)
The capitalized identifiers (FileNamed, ForPurpose) describe an argument’s type. The immediately following lowercase identifiers give the code that implements open_file names that it can use to refer to values passed down through the API. In one particular use of open_file, name might refer to “my file” and purpose to ToRead. The next use might give different values.
One more detail:
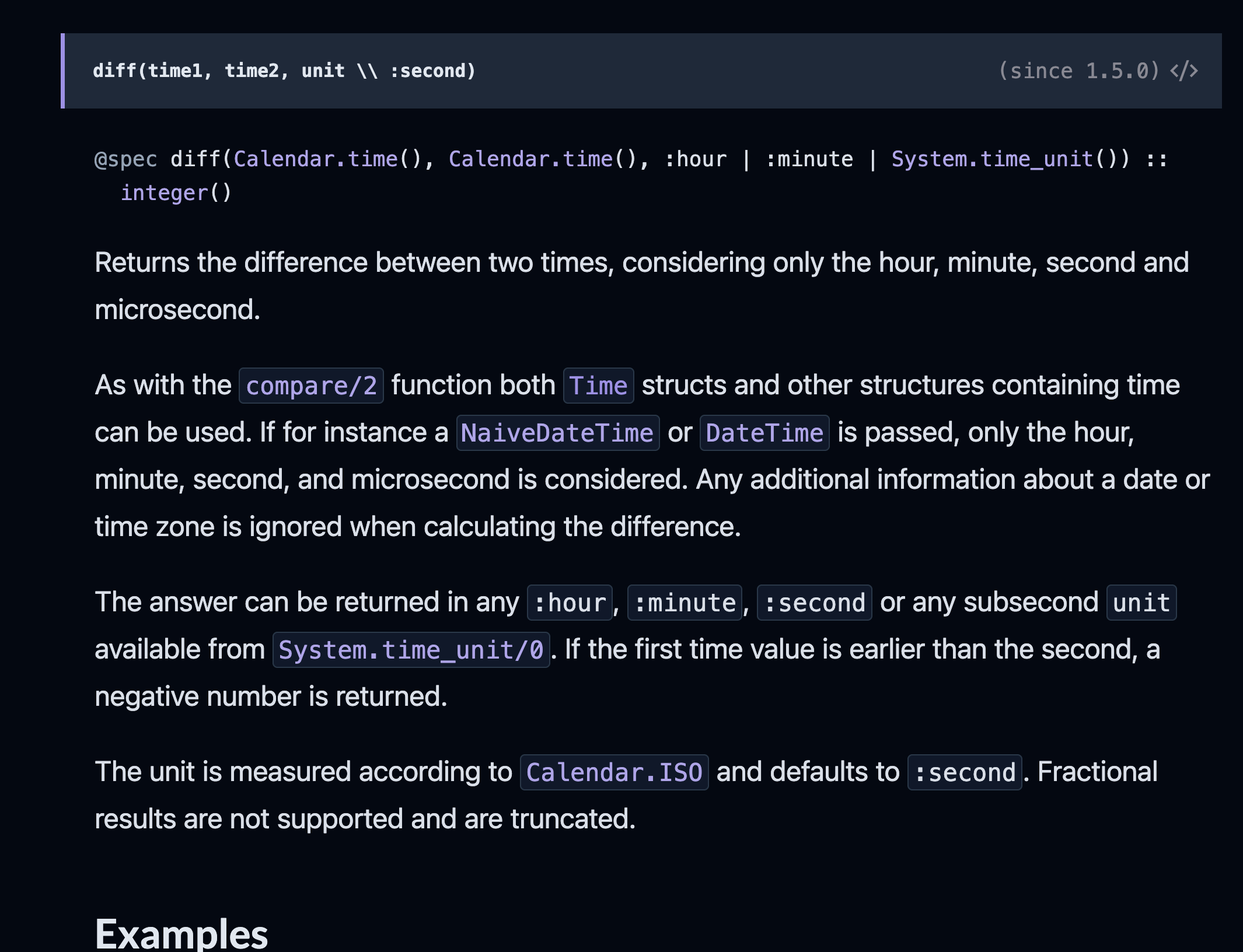
Let’s suppose there’s another function named transfer that transfers text from one open file to another. That function might “return a result.” That would look like this:
transfer(OpenFile from, OpenFile to, Count how_much) returns TransferResult
^^^^^^^^^^^^^^^^^^^^^^
TransferResult can be casually described as one of:
- “Everything went fine.” Whatever number of characters was intended to be transferred has been transferred.
- “Only 5 of the intended 34355 characters made it.”
- “You opened the
fromfile wrong: it can only be written to, not read from.” - “You opened the
tofile wrong: it is read-only.”
That is all the computer science you need to know to understand the rest of this post.
A formative experience

Back then, the dominant rule-set for proper programmer behavior was the “waterfall methodology,” and our project followed it. The senior programmers were to design the API first. The physical form of the design was a set of short documents (“man pages”), one per function. Each man page started with a description of the function (like the ones for open_file and transfer in the optional section above). That strict definition of function names, argument types, and return value types was followed by natural-language text saying what the function did, how to use it, what the different possible return values meant, etc.
My main role on the project was to test the implementation. At that time, the conventional wisdom was that programmers couldn’t test their own code (find their own bugs). Since programmers of that era didn’t like testing anyway, they were happy to delegate the job to juniors like me. But there wasn’t an implementation to test yet – that would come after the design was finished and approved. So my job during the design “phase” was to write user documentation – to explain how to put the various functions together to accomplish some goal. An app will usually use more than one function from an API. Typically, a sequence of “calls” to different functions is needed to accomplish a particular goal.
My approach was to organize the document around one or more annotated examples. “If you want to do something like X with this API, here’s an annotated sample program that shows you how.” I couldn’t actually check if the examples worked until the implementation was finished, but I could get most of the documentation work done while I had nothing else to do.
While writing an example, I discovered an interesting problem (a bug in the design). There was a function in the API that took a magic Key value (something like a modern passkey). In at least my scenario, there was no way to produce that key. Thus, the task I was showing app programmers how to accomplish was in fact impossible.
Critical rationalism is like that
If I’m to think of critical rationalism as an API, I will, and say it’s an incomplete API like ours from the ’80s. So many entities are supposed to just appear, as with the Key argument that one function required and no function supplied. Experimental design: irrelevant to theory! Evaluating experimental results: hard in theory but someone else’s job in practice! Predictions: pure deductive logic suffices! Confirmations/refutations: simple binary values, no details needed! Collaboration: what does that have to do with anything?
The people I worked with in 1985 were fine people. The only one who I can actually picture in my mind was impressively smarter than me. But, if a methodology is equivalent to an API, what critical rationalism is missing makes it unable to accomplish actual science in the way the original as-designed SELUnix API would have been unable to support a flight simulator.
So who cares, and why should they?
As Konrad Hinsen has pointed out to me, I’m sort of smashing a gnat with a sledgehammer, since real scientists don’t actually follow the critical rationalist methodology and most everyone knows that. Scientists do what works, not what non-scientists tell them what to do.
Granted, but my career was in a field (software development) where it’s a cottage industry to take naive views of how other people do their jobs and then proclaim “we should be like them.” The very term “software engineering” is an example. It was a successful imposition of methodology supposedly used by Real Engineers – with, I think, inadequate consideration of what engineers actually do. As with the critical rationalists, a distaste for the squishy, non-logical, sociological parts of engineering meant that their comparisons of programming to designing and building bridges or intercontinental ballistic missiles were… fraught. Postscript: It’s been a while since I read the primary sources in software engineering. I have a feeling I’m maybe being unfair: they may have shown more concern for such matters than the (roughly contemporaneous) critical rationalists did. To get real work done, you had to pay attention to parts of the job they’d ignored and, realistically, at least bend the rules if not ignore some rules entirely. “This book is about doing testing when your coworkers don’t, won’t, and don’t have to follow the rules.” – Testing Computer Software (2/e), Kaner, Falk, and Nguyen, 1993.
The overall status of science has varied in the popular imagination. In my country (the USA), science’s reputation is currently at a low ebb. But there are still subcultures with high regard for science. I’m arguing that such science fans shouldn’t listen to people like the critical rationalists – they have a few useful ideas that you’ve already absorbed from the zeitgeist, combined with a bunch of abstract wankery you should ignore.